
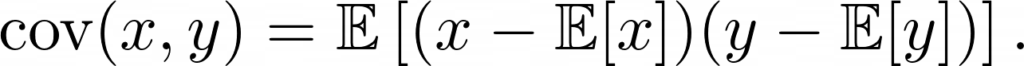
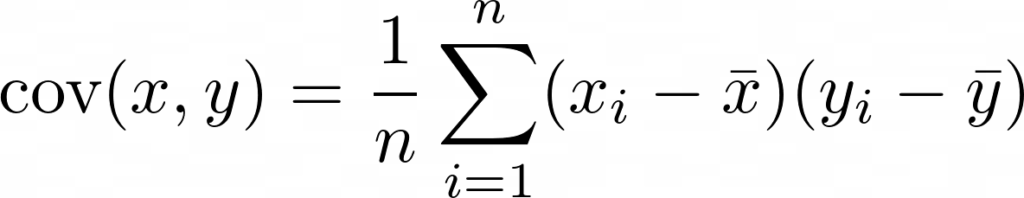
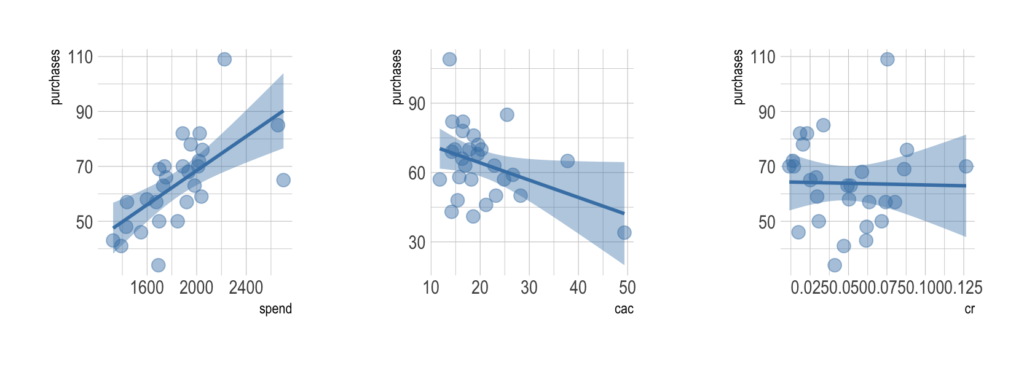
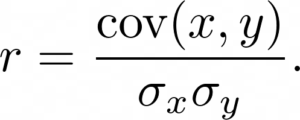
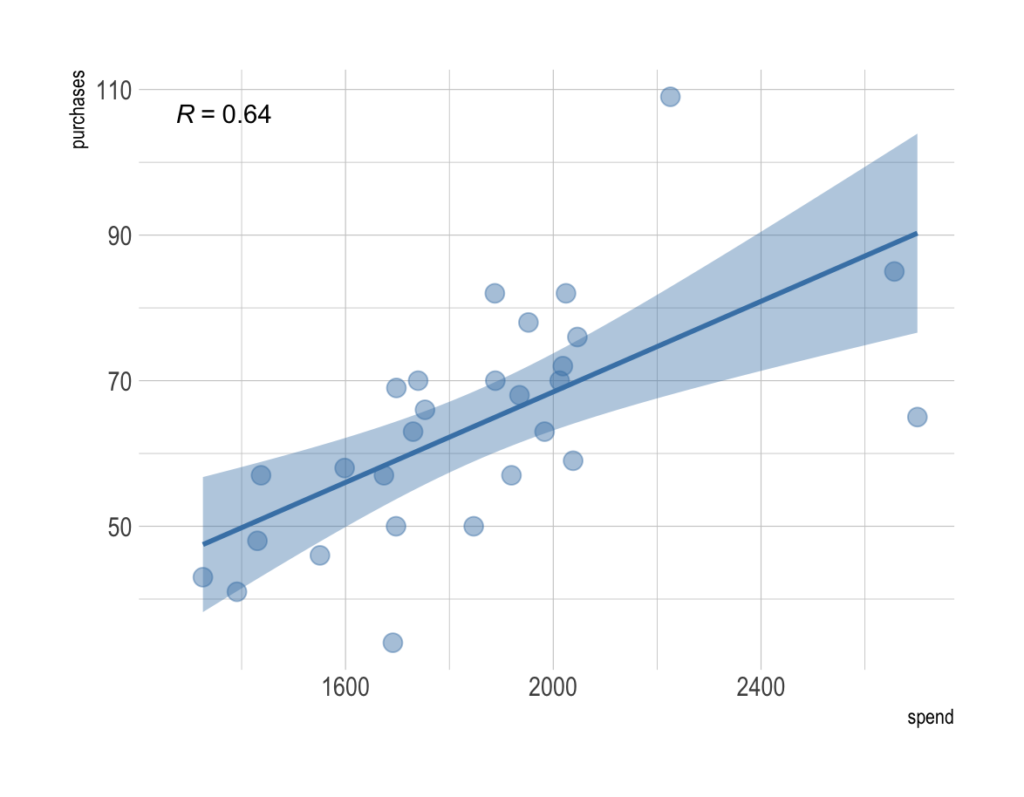
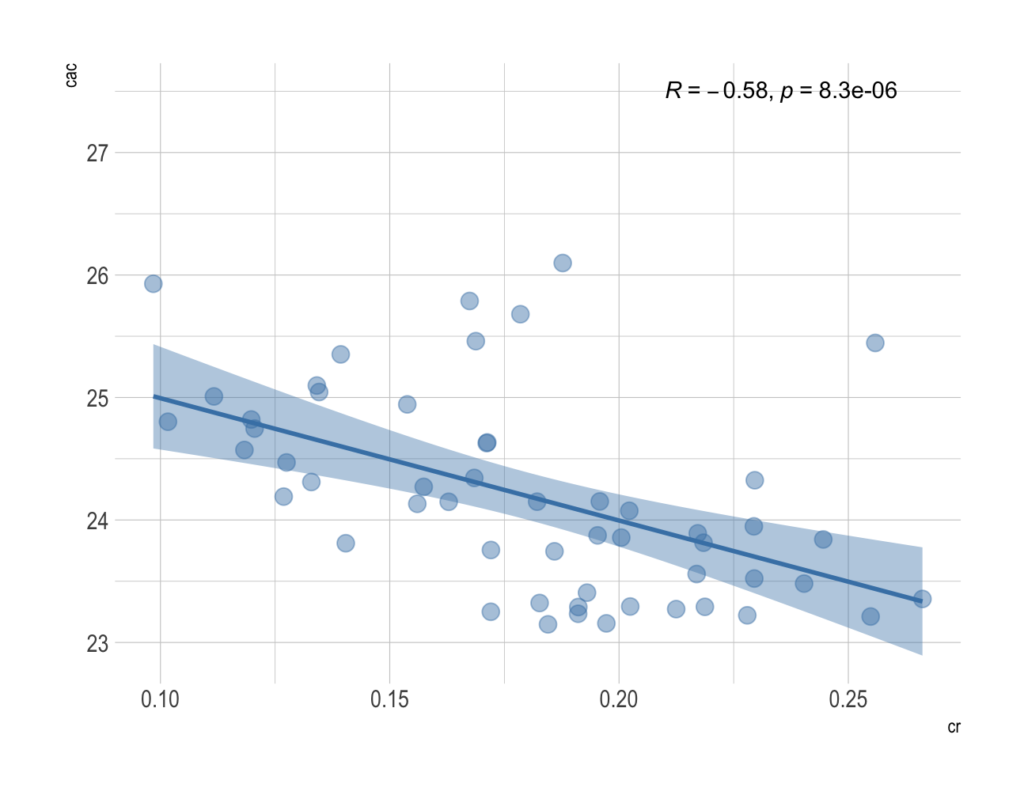
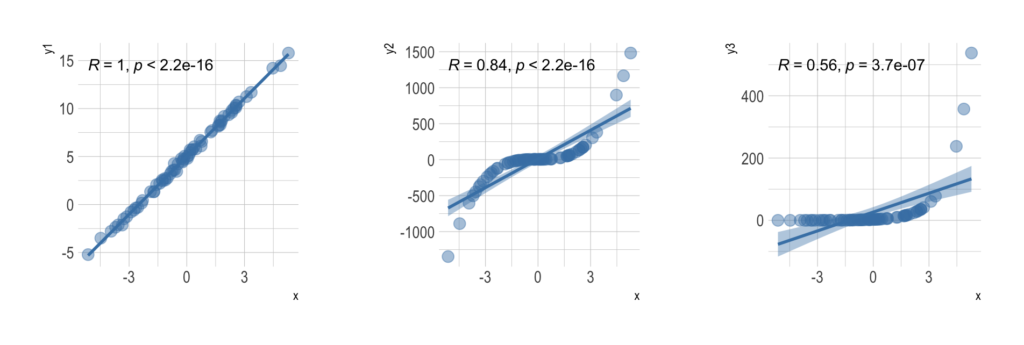
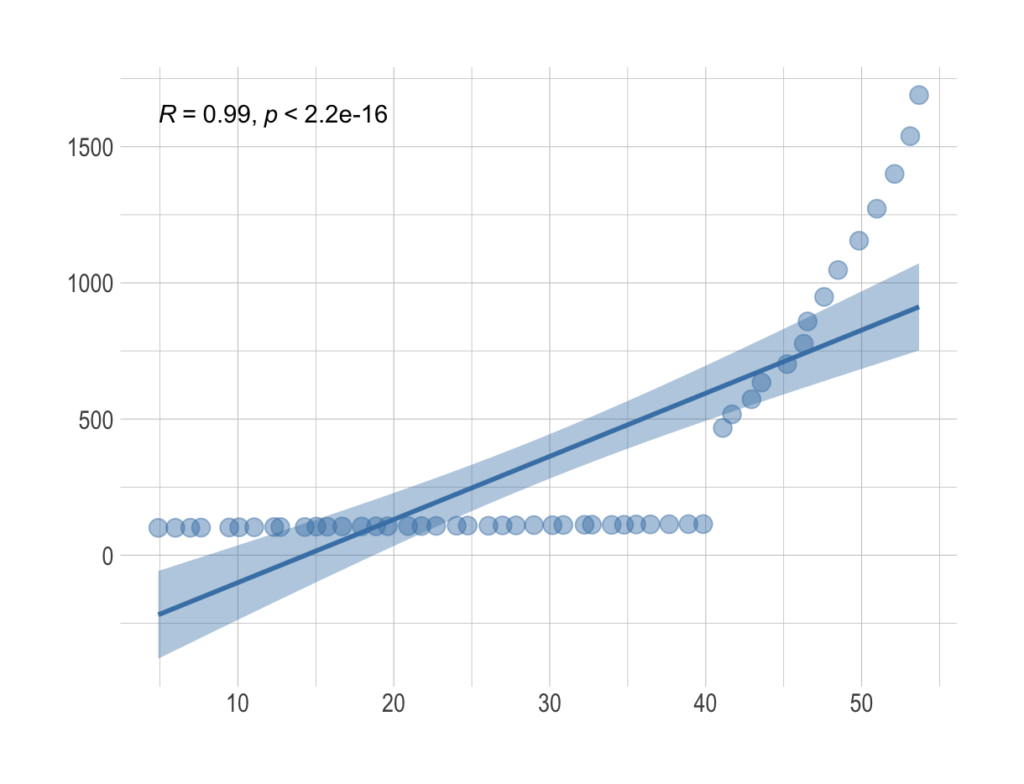
Pearson’s r is a continuous metric that falls in the range [-1, 1]. It is 1 in the case of a perfect positive linear association between the two variables, and -1 for a perfect negative linear association. If there is little or no linear association, r will be near 0. A negative r means that the variables are inversely related.
On a scatter plot, data with perfect association would have all points along a straight line. This makes r an easily interpreted metric to assess whether two variables have a close linear association or not.
By squaring the value of the coefficient, we get the coefficient of determination, which we denote by . It determines how much variation of the data is explained by the linear model.
Spearman’s rank correlation coefficient (rho) is a nonparametric (distribution-free) rank statistic proposed as a measure of the strength of the association between two variables. It is a measure of monotone association used when the distribution of data makes Pearson’s r undesirable or misleading. Intuitively, if we have a set of n pairs
, we replace the data pairs with their ranks, and compute Pearson’s correlation coefficient based on the ranks.
This assesses how well an arbitrary monotonic function can describe the relationship between two variables, without making any assumptions about the distributions. So, rs shows if there is a monotone relationship between two variables and we can interpret it as follows:
– There is no monotonic connection
– There is a growing connection
– There is a falling connection
This coefficient is used when at least one variable is ordinal. We calculate it using derived expressions:
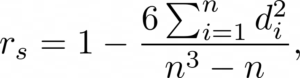
where is rank difference. For a detailed derivation of the formula, see the following link. If the data is correlated, then the sum of squares of the difference between ranks will be small. Depending on the amount, the correlation may or may not be significant.
Tau () is another nonparametric rank correlation coefficient that is used to understand the strength of the relationship between two variables. It is in the same range as other correlation coefficients. Its value characterizes the degree of agreement between variables.
As a rank correlation statistic, indicates how similarly two variables order a set of individuals or data points. The distribution of Kendall’s tau has better statistical properties, see here
Any pair of observation , where
are said to be concordant if the sort of pairs agree, i.e. if one of the following cases holds
Otherwise, a pair is discordant. In other words, a pair is concordant if both members of one observation are larger than their respective members of the other observations. The formula for calculating this coefficient is:
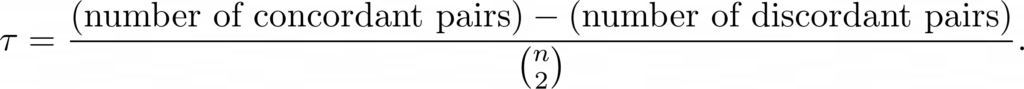
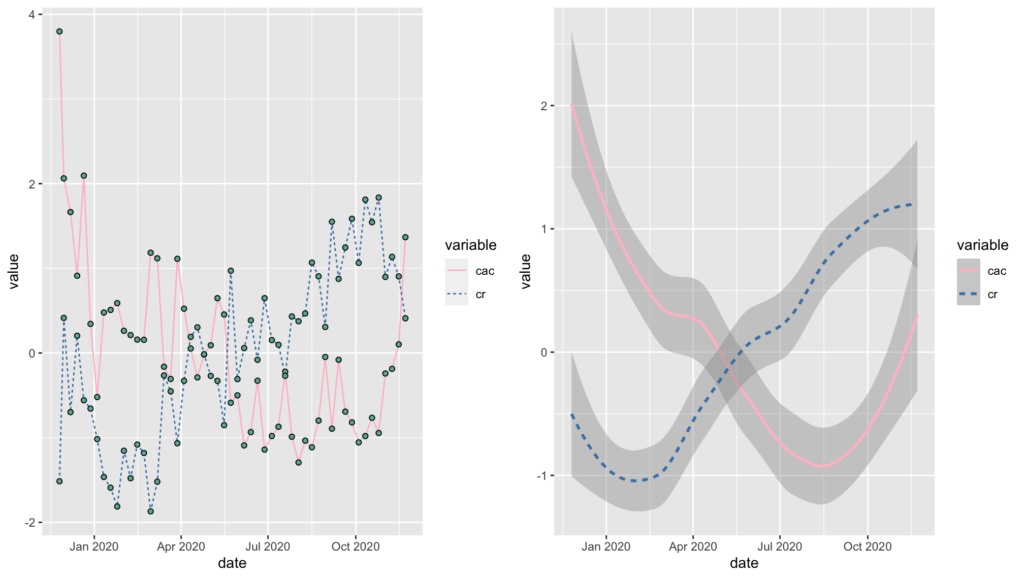
In more detail, the basis of this test is the number of times the data increases or decreases through time. The interpretation of Kendall’s tau in terms of the probabilities of observing the concordant and discordant pairs is very direct.
Consequently, is interpretable as the percentage of pairs of data points that show a positive correlation, which we explained in more detail in the example. Kendall’s is equal to Spearman’s rho in terms of the underlying assumptions, but their underlying logic and formulae are quite different.
In most cases, these values are very close and would invariably lead to the same conclusions, but when discrepancies occur, it is probably safer to interpret the lower value ( ). One advantage of Spearman’s rank correlation coefficient over Kendall’s is that is easier to calculate, particularly for larger data sets.
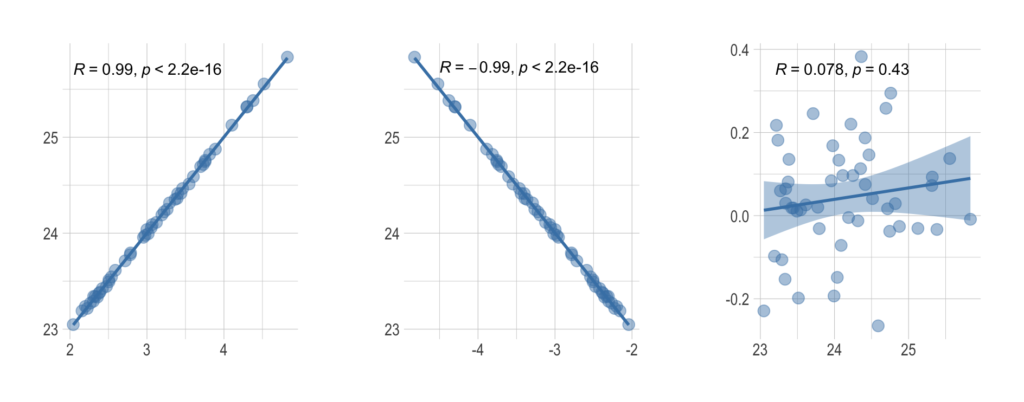
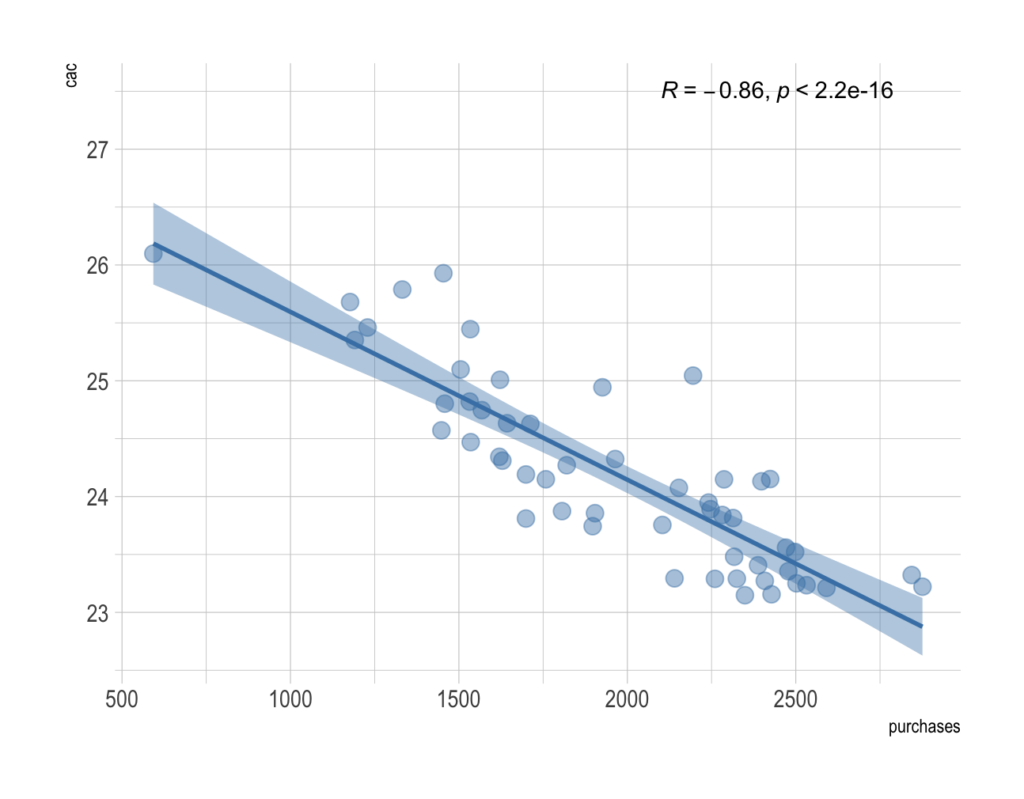
Before reaching a conclusion, it is necessary to conduct a correlation test. We need to test the hypothesis for the significance of the correlation coefficient. The corresponding hypotheses for conducting that statistical test are:
where r is some correlation coefficient. The level of statistical significance is often expressed as a p-value between 0 and 1. The smaller the p-value, the stronger the evidence that we should reject the null hypothesis.
For example, we can interpret p-value of 0.05 as: assuming that the correlation coefficient is zero, we’d obtain the sample effect, or larger, in 5% of studies because of random sample error. For more details explore this link.


No comment yet, add your voice below!