
If you still didn’t read our wonderful article about why building a smart recommendation system matters, you should definitely go ahead and read it. For those of you who have already done their homework, creating efficient retargeting campaigns on Facebook, or recommending personalized products to a customer via email prospecting campaigns is now, thanks to our app, not only a dream, but a reality. Just click the download button in the app and leave the heavy lifting to us!

Great, right? For most people. But maybe you are one of those who really like to go into technicalities and needs to know everything about everything. Well, don’t worry because we got you covered – in this article we will show you exactly what happens when you click the download button.
A simple introduction
As an easy introduction to our more complex solution, we recommend you read our article about exploring next-product preferences through a probability change matrix. Namely, using such a simple “recommendation system”, we showed how taking into account even only the first product a customer bought can help us understand his preferences in more detail. Here we will show you how to use the complete purchase history of a customer to make the most of your data.
The data we missed
After a customer makes a purchase at your shop, you immediately get a lot of information about them:
- which products they purchased,
- how many times,
- how much they spent,
- how often they purchase,
- when was the last time they made a purchase.
You might also have some additional information about the customer’s location, sex, age, etc. A lot of research was done about analysing which variables are the best indicators for next product recommendations. If you are interested in reading more about this, we would recommend Knott A., Hayes, A., and Neslin, S.A. (2002). Next-product-to-buy models for cross-selling, where the authors made a thorough case study comparing different next-product-to-buy models. One of the main conclusions from the article is that demographics and monetary variables add predictive power to the model, but product ownership is the single most valuable predictor.
Model selection
In theory, any model for multi-class classifications could work here:
- Multinomial logistic regression,
- SVM,
- Naive bayes,
- Neural Network,
- Discriminant analysis,
- etc.
We chose a Neural Network model since through our research and testing on multiple stores it showed to be the best one. Nevertheless, some of the other models can also have a similar level of performance like neural networks, but we didn’t see any of them outperforming neural networks.
Train smart.
Training your model can be a bit tricky since only customers with repeat purchases are useful for training your model. Until you get a fair number of those, there is no point in trying to do smart retargeting: no model can be trained without a substantial amount of data. However, for shops with enough data, we can create a training set by setting the last product each customer bought as the target, while all products previously bought are used as feature variables.
Test dumb.
When talking about testing our model, there is one important metric we check for our final model: does it have better performance than a dummy model? We use two dummy models:
- Random model: predicts a random product out of all products a customer didn’t buy.
- Next-top model: predicts the best selling product out of all products a customer didn’t buy.
Random models should be easy to beat with almost any meaningful model, but Next-top models can sometimes be unexpectedly precise.
Example
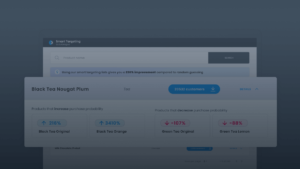
To demonstrate this, let’s look at the following example: in the table below we can see top purchased products for a store. If you sum up the percentages for the first three products, you can conclude that they take up more than 90% of overall purchases.
Title | % Orders |
Black Tea Original | 48.23% |
Green Tea Original | 31.71% |
Black Tea Nougat Plum | 10.98% |
… | …… |
Let’s say we want to send an email with three products recommended for each of our customers. If we always recommend the top three products, no matter which customer, we will obviously have a 90% precision, just because those three products are the most popular products overall and customers buy them anyway. Consequently, for this shop a good model should have a precision higher than 90%, while in some other cases even 60% could be considered a good precision.
In the table below you can see the initial results we’ve got for a sample of ten anonymous stores. Improvement is calculated as
improvement = (precision_nnet/precision_dummy – 1)*100%.
Precision Improvement Against Next-Top Model | Precision Improvement Against Random Model | |
Store 1 | 144.86% | 324.26% |
Store 2 | 45.95% | 145.45% |
Store 3 | 63.11% | 158.46% |
Store 4 | 114.29% | 200.00% |
Store 5 | 22.62% | 156.96% |
Store 6 | 17.74% | 97.30% |
Store 7 | 82.43% | 350.00% |
Store 8 | 19.35% | 260.98% |
Store 9 | 35.90% | 261.36% |
Store 10 | 26.26% | 498.65% |
Average | 49.98% | 204.28% |
As expected, the improvement compared to the random model is very high, around 200%, meaning that the neural net precision is usually 3x higher than the precision of a random model. More importantly, there is a significant improvement compared to the next-top model. Of course, these improvements vary and depend mostly on the number of products of the store and the distribution of top products.
Conclusion
In conclusion, nobody expects to have a recommendation system with a 100% precision , but if you can’t do better than a dummy, then you are not able to provide any additional value, no matter how fancy a model you choose. This is why we put a lot of effort into testing across multiple shops and finding the best models that can give our customers meaningful recommendations. As a result, we have seen the precision going up for 2.5 times by using our smart recommendation system.
If you own a Shopify store, be sure to try our smart recommendation system yourself by installing our app!

No comment yet, add your voice below!